
author
type
Post
status
Published
date
Nov 21, 2024
slug
summary
tags
监控
category
Prometheus和Grafana监控平台
icon
password
Kubernetes 集群监控
服务发现简介
service discovery(服务发现)通常不属于 Prometheus 本身的层次结构,因为 Prometheus 主要是一个监控系统和时间序列数据库,而不是一个服务发现工具。然而,Prometheus 可以与各种服务发现机制集成,以便自动发现和监控需要监控的目标。在 Prometheus 的架构中,服务发现通常发生在配置管理的过程中,这是 Prometheus 监控流程的一部分。具体来说,Prometheus 使用服务发现来动态地获取和更新监控目标的列表。这些目标可以是 Kubernetes Pods、Docker 容器、云服务实例等。Prometheus 支持多种服务发现机制,包括但不限于:
- 文件服务发现:通过读取文件中的目标列表。
- Kubernetes 服务发现:自动发现 Kubernetes 集群中的服务和 Pods。
- Consul 服务发现:与 Consul 集成,发现 Consul 中的服务。
- EC2 服务发现:在 AWS EC2 环境中自动发现实例。
- node:从集群中发现节点并将其添加为监控目标
- service:从集群中发现Service并将其添加为监控目标,主要用于监控Service的可用性
- pod:从集群中发现pod并将其添加为监控目标,主要用于监控的pod中应用程序
- endpoint和endponintslice:从service的Endpoints 对象中发现Pod并将其添加为监控目标
- ingress: 从集群发现Ingress 并将其添加为监控目标,主要用于监控Ingress 的可用性和Http处理性能
在 prometheus-cm.yaml 下 scrape_configs一次添加如下采集数据
Kubernetes 关注指标
监控目标 | 关注指标 |
Node | CPU利用率
内存利用率
硬盘利用率
网络流量 |
Pod | CPU利用率
内存利用率
网络流量 |
资源对象 | 工作负载类控制器资源对象的副本状态
Pod运行和非运行数量
其他资源状态 |
Service和Ingress | 可用性
HTTP请求时间延迟成功率等 |
K8s组件 | 运行状态
工作性能 |
Pod中的应用程序 | 自主开发的指标接口 |
监控Node
为了监控主机的资源利用率 ,通常会在目标主机上部署Node Exporter,通过静态配置方式添加监控目标监控集群中的节点也是同样道理,而且使用Daemonset管理NodeExporter会更加方便收集Node Exporter指标流程如下图
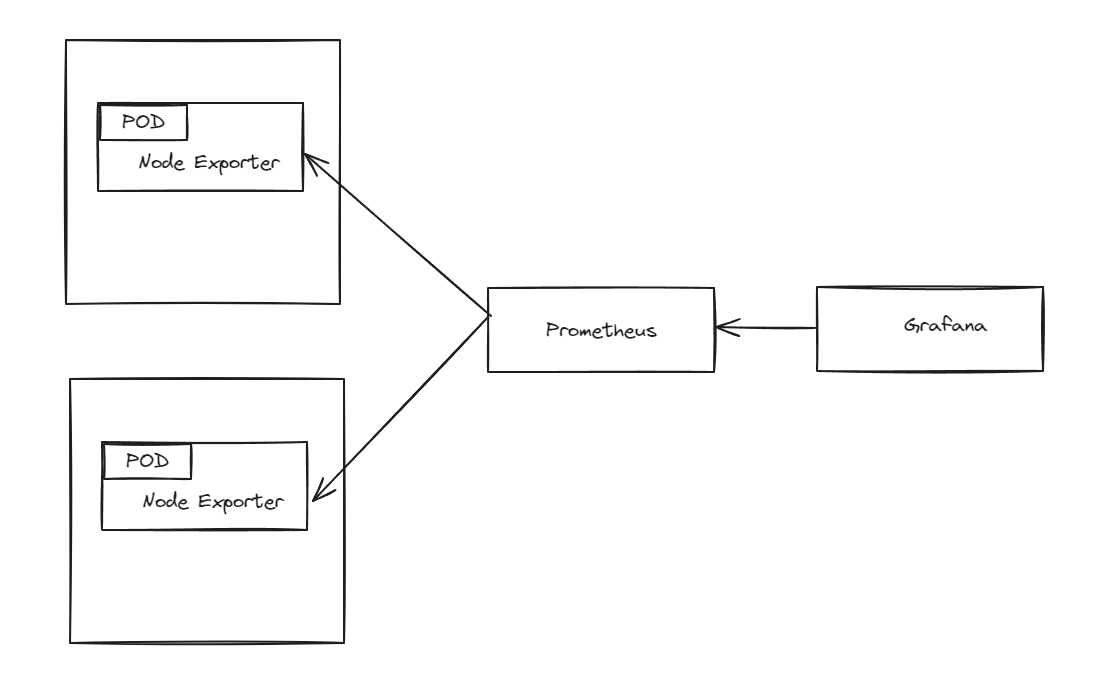
node-exporter部署
Node Exporter 是 Prometheus 官方提供的一个节点资源采集组件,可以用于收集服务器节点的数据,如 CPU频率信息、磁盘IO统计、剩余可用内存等等
由于是针对所有K8S-node节点,所以我们这边使用DaemonSet这种方式vim node-exporter.yamlnode_exporter.yaml文件说明:hostPID:指定是否允许Node Exporter进程绑定到主机的PID命名空间。若值为true,则可以访问宿主机中的PID信息
hostIPC:指定是否允许Node Exporter进程绑定到主机的IPC命名空间。若值为true,则可以访问宿主机中的IPC信息
hostNetwork:指定是否允许Node Exporter进程绑定到主机的网络命名空间。若值为true,则可以访问宿主机中的网络信息
验证配置服务发现
自动发现pod在 WebUI可用看到集群所有pod均被添加为监控目标
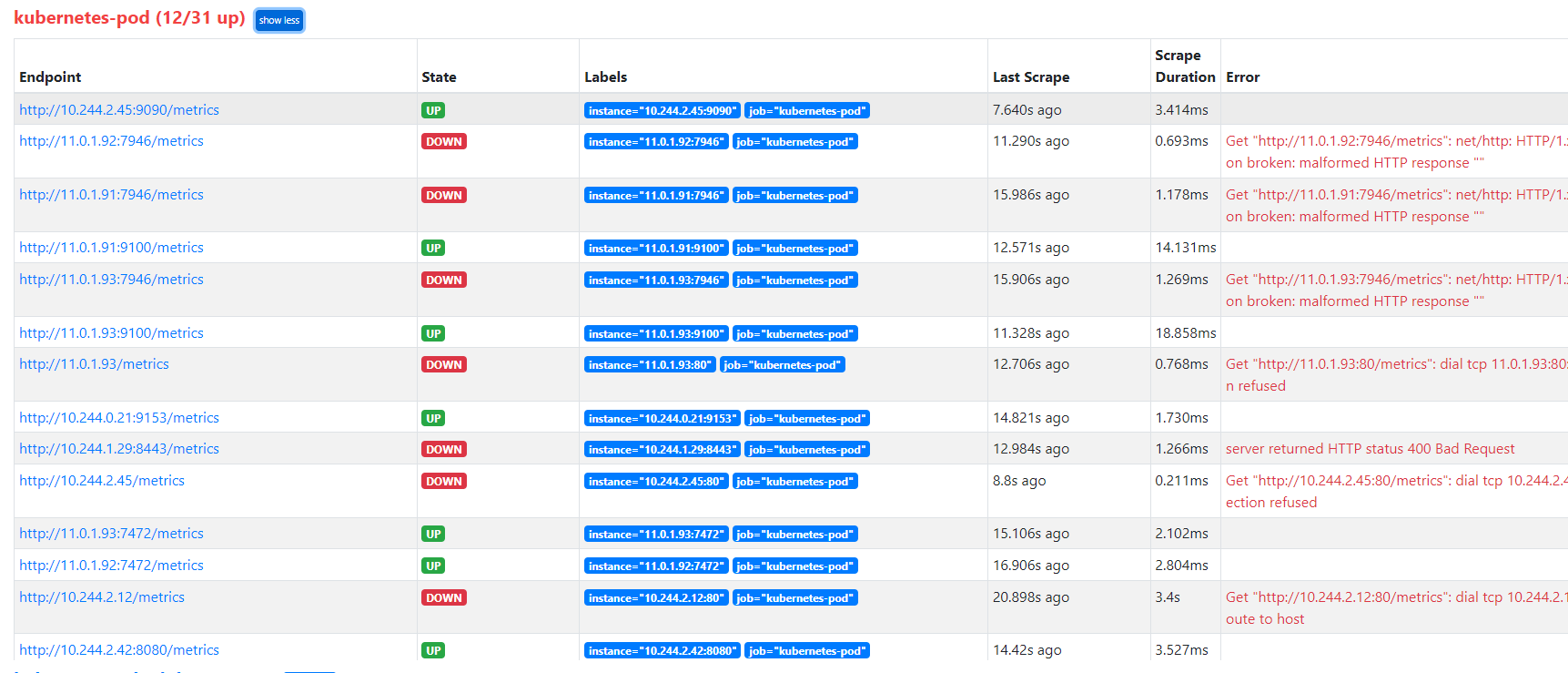
其中大部分Pod由于没有配置指标端口 状态为DOWN 而Node Exporter 的相关Pod已被监控为了减少不必要的监控目标,可以利用标签重写功能,根据条件选择要保留的监控目标,配置如下
保留这个__meta_kubernetes_pod_annotation_prometheus_io_scrape 元标签 且值为true的pod才会被抓取监控
给pod加一下注解修改node-exporter.yaml可以看出 只监控到 符合条件pod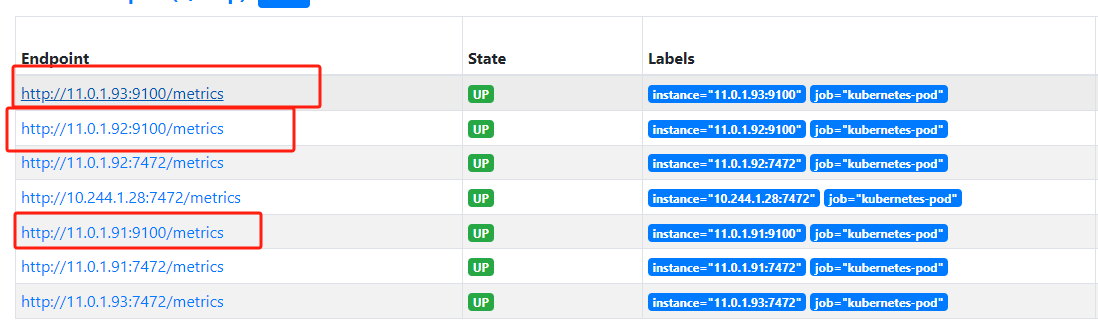
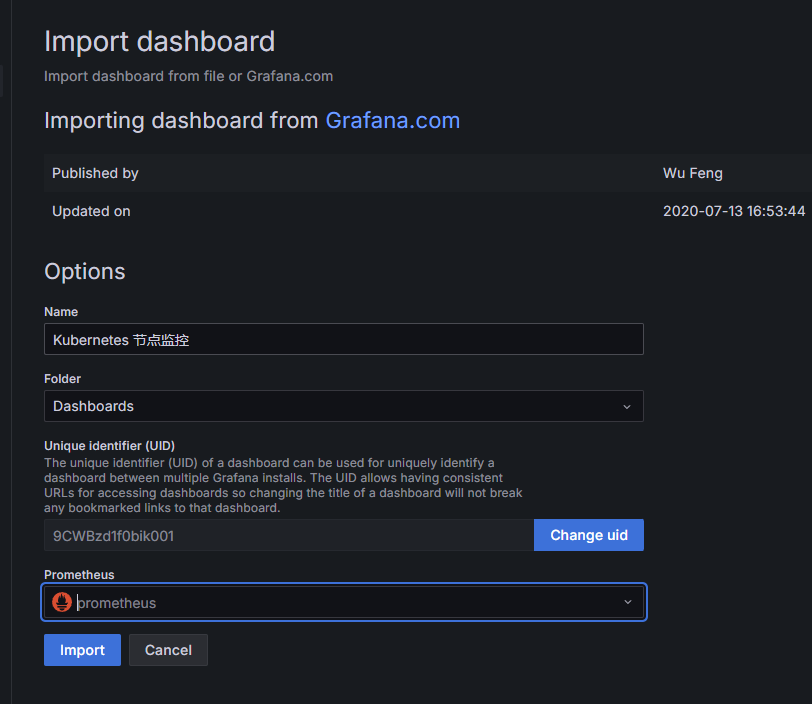
Grafana导入仪表盘
Grafana 导入 输入仪表盘ID 12633 并将名称设置为Kubernetes节点监控 导入完成后将仪表盘界面 如图所示
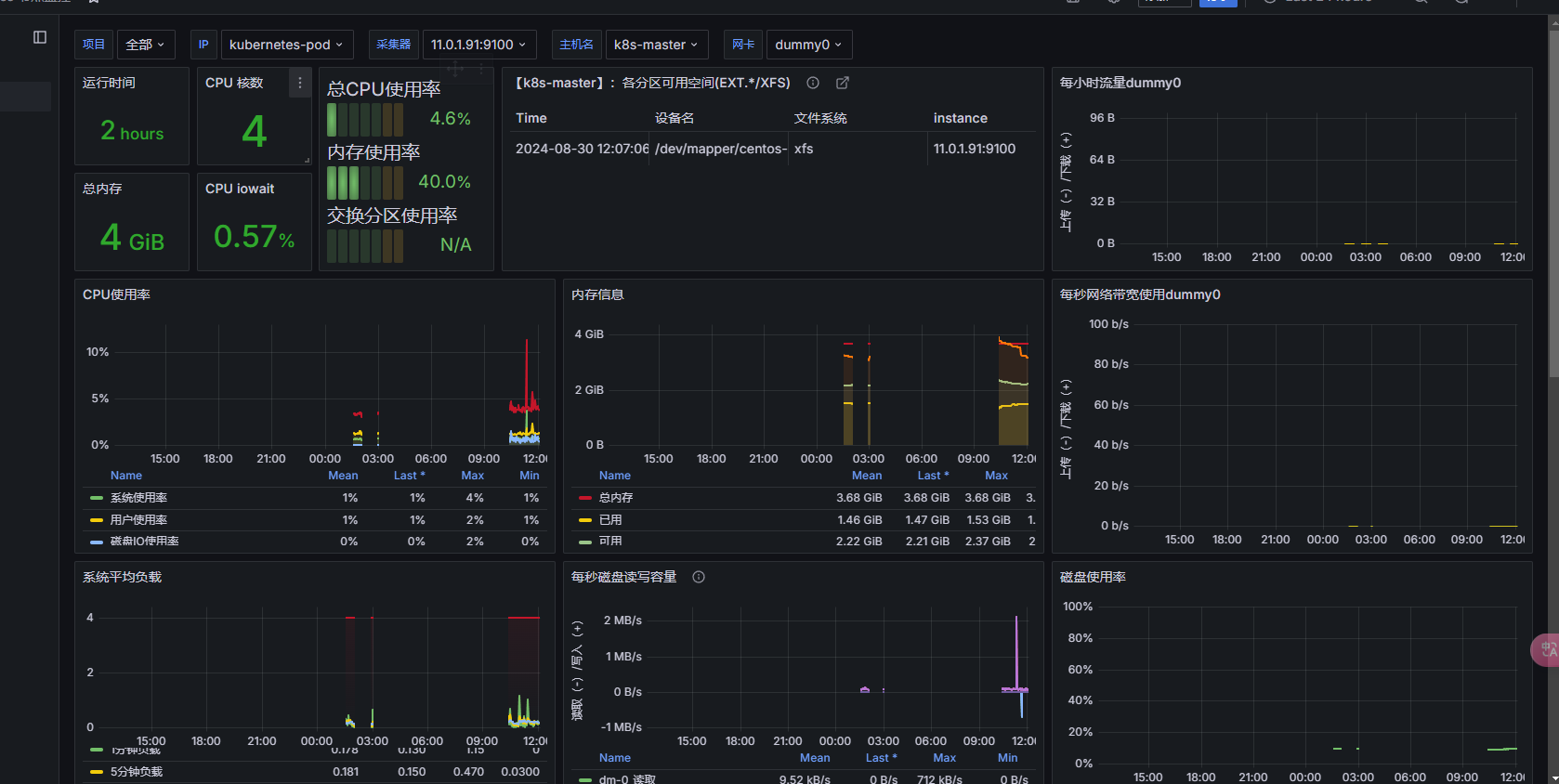
监控pod
为了监控Docker主机上容器的资源情况,通常会在目标主机上部署cAdvisor Exporter,并通过静态配置方式添加监控目标cAdvisor已经被内置在kubelet组件中,并通过kubelet API暴露cAdvisor才采集数据用户无须再而外部署cAdvisor,只需自动发现节点的kubelet并将其添加监控目标即可收集cAdvisor指标流程如图所示
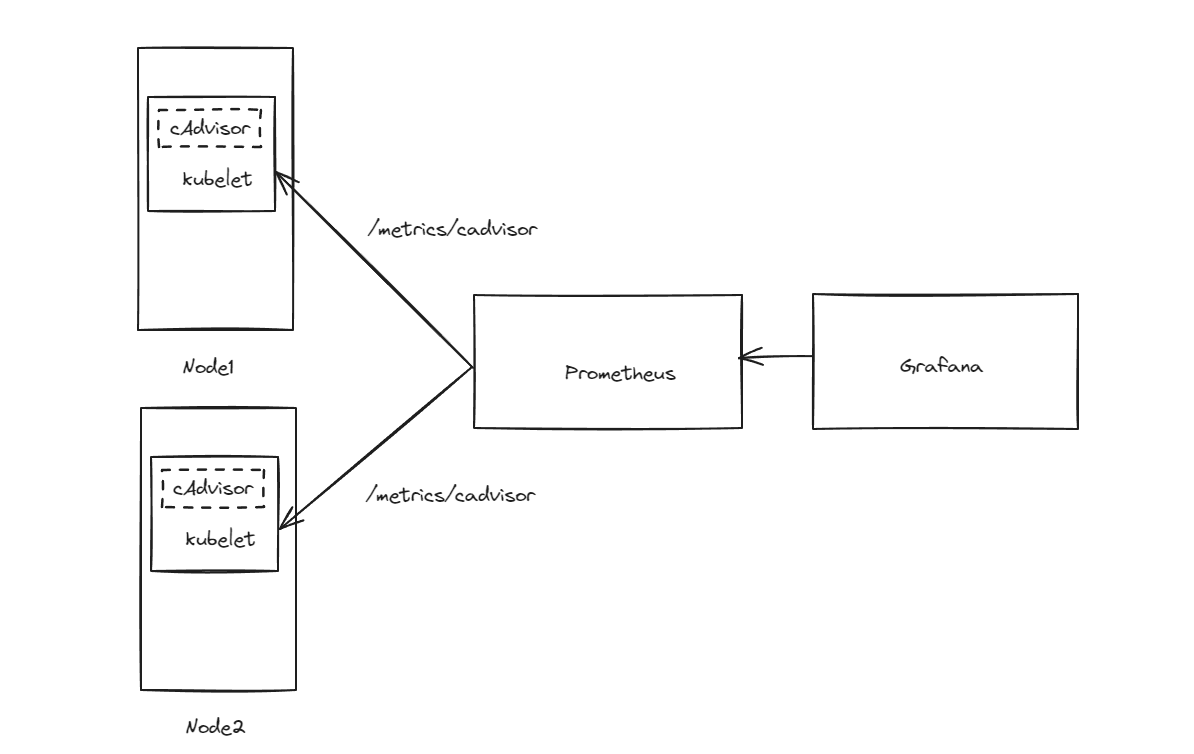
配置服务发现上面job 并使用Kubernetes服务发现通过标签重写功能,默认的指标接口路径被替换成/metrics/cadvisor 这个cAdvisor通过kubelet API暴露指标接口
设置热加载WebUI 查看监控接口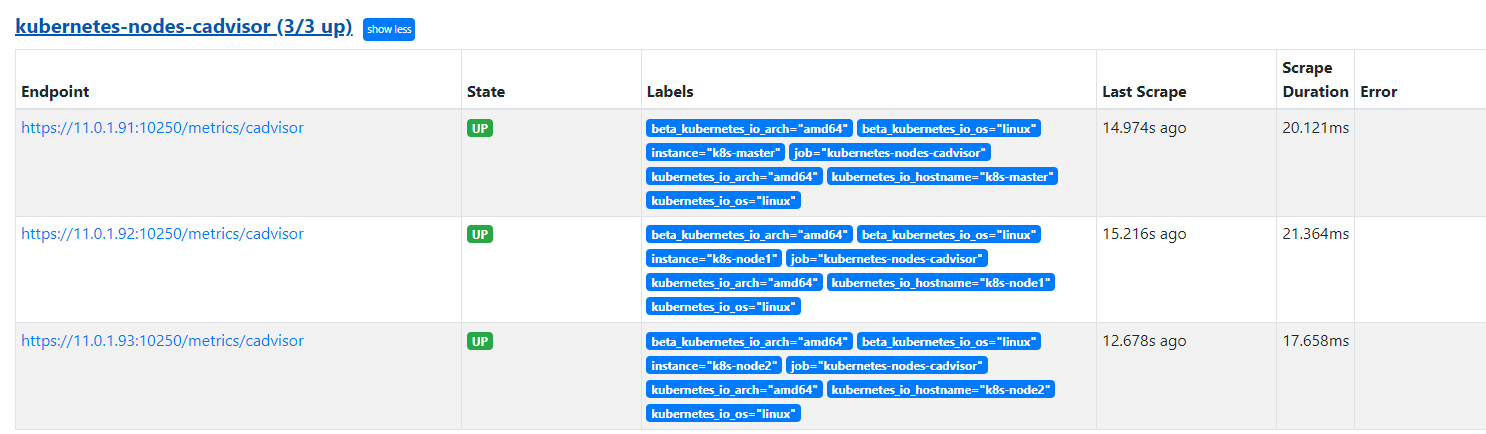
监控Kubernetes组件
各组件指标接口信息组件名称 | 端口 | 协议 | 指标 |
etcd | 2381 | http | 请求数量,延迟,存储空间等 |
kube-apiserver | 6443 | https | 请求数量,请求延迟 |
kube-controller-manager | 10257 | https | 各个控制器的同步次数,工作队列等 |
scheduler | 10259 | https | 调度决策数量,延迟等 |
kubelet | 10250 | https | 启动pod/容器总数,运行pod/容器数量等 |
kube-proxy | 10249 | http | 同步代理规则的总次数,同步代理规则延迟等 |
coredns | 9153 | http | 请求数量,转发DNS请求数量 |
ingress控制器 | 10254 | http | 客户端请求总数,连接数,CPU/内存使用等 |
etcd组件监控
用 kubeadm部署k8集群 etcd默认以静态pod部署的,可以通过http://127.0.0.1:2381/metrcis 来查看etcd指标数据
接口默认服务监控127.0.0.1 为了实现外部可以访问抓取数据 可以把--listen-metrics-url参数的值改为"http://0.0.0.0:2381"
在prometheus 配置文件中添加服务发现
vim prometheus-cm.yaml上述添加 kubernetes-etcd job 然后使用endpoint类型自动发现Endpoint 对象关联pod并添加为监控目标
[!NOTE]使用endpoint类型需要存在service 所以 要创建 一个 ectd svc
vim etcd-svc.yaml热加载Web UI查看etcd pod 监控目标

kube-apiserver组件监控
kube-apiserver组件与etcd部署方式一样的 但它已经创建Service 因此直接使用endpoint类型服务发现即可

指标 | 类型 | 说明 |
apiserver_request_total | Counter | 所有请求的总数 |
apiserver_request_duration_seconds_sun | Histogram | 请求的总处理时间 |
apiserver_request_duration_seconds_bucket | Histogram | 请求处理时间的分布情况 |
apiserver_request_duration_seconds_count | Histogram | 请求的次数 |
kubernetes-controller-manager组件监控
同样是pod静态部署 为了外部抓取数据 需要放行端口 需要修改监听地址
添加job添加 service
指标 | 类型 | 说明 |
workqueue_adds_total | Counter | 工作队列处理Adds事件的数量 |
workqueue_depth | Gauge | 工作队列当前队列深度 |
workqueue_queue_duration_seconds_sum | Histogram | 工作队列所有任务的总执行时间 |
workqueue_queue_duration_seconds_bucket | Histogram | 工作队列任务执行时间的分布情况 |
workqueue_queue_duration_seconds_count | Histogram | 工作队列任务的次数 |
kubernetes-scheduler组件监控
和kubernetes-controller-manager做法是一样的
添加job添加 service

指标 | 类型 | 说明 |
scheduler_pending_pods | Gauge | Pending状态的Pod数量 |
scheduler_scheduler_cache_size | Gauge | 调度器缓存Pod AssumedPod和Node的数量 |
scheduler_pod_scheduling_duration_seconds_sum | Histogram | Pod调度的总处理时间 |
scheduler_pod_scheduling_duration_seconds_bucket | Histogram | Pod调度时间分布情况 |
scheduler_pod_scheduling_duration_seconds_count | Histogram | Pod调度的次数 |
kubernetes-kube-proxy 组件监控
和kubernetes-controller-manager做法是一样的
放行端口添加job添加service
指标 | 类型 | 说明 |
kubeproxy_sync_proxy_rules_iptables_total | Gauge | 管理Iptables规则 |
process_cpu_seconds_total | Counter | kube-proxy进程使用CPU时间总量 |
process_virtual_memory_bytes | Gauge | kube-proxy进程使用的虚拟内存量单位为字节 |
process_virtual_memory_max_bytes | Gauge | kube-proxy 进程可以使用的最大虚拟内存单位为字节 |
coredns组件监控
添加job
指标 | 类型 | 说明 |
coredns_dns_requests_total | Counter | DNS请求的总数 |
coredns_dns_request_duration_seconds_sum | Histogram | DNS请求的总处理时间 |
coredns_dns_request_duration_seconds_bucket | Histogram | DNS请求处理时间到分布情况 |
coredns_dns_request_duration_seconds_count | Histogram | DNS请求的次数 |
coredns_forward_requests_total | Counter | 转发DNS请求的总数 |
coredns_forward_request_duration_seconds_sum | Histogram | 转发DNS请求的总处理时间 |
coredns_forward_request_duration_seconds_bucket | Histogram | 转发DNS请求处理时间的分布情况 |
coredns_forward_request_duration_seconds_count | Histogram | 转发DNS请求的次数 |
kubelet组件监控
添加job
指标 | 类型 | 说明 |
kubelet_running_pods | Gauge | 运行Pod的数量 |
kubelet_running_containers | Gauge | 运行容器的数量 |
process_cpu_seconds_total | Counter | Kubelet进程使用的CPU时间总量 |
process_virtual_memory_bytes | Gauge | Kubelet进程使用的虚拟内存量,单位为字节 |
process_virtual_memory_max_bytes | Gauge | kubelet进程可以使用的最大虚拟内存,单位为字节 |
ingress-controller组件监控
vim prometheus-cm.yaml在 ingress svc 添加 metrics 端口规则
监控集群中应用程序
监控Service和Ingress对象
监控资源对象
KubeStateMetrics简介
kube-state-metrics(简称KSM) 是一个 Kubernetes 组件,它通过查询 Kubernetes 的 API 服务器,收集关于 Kubernetes 中各种资源(如节点、pod、服务等)的状态信息,并将这些信息转换成 Prometheus 可以使用的指标
项目地址
以下是 版本支持 k8s版本
kube-state-metrics | Kubernetes Version |
v2.3.0 | v1.22 |
v2.4.2 | v1.23 |
v2.5.0 | v1.24 |
v2.7.0 | v1.25 |
v2.8.2 | v1.26 |
v2.10.1 | v1.27 |
v2.11.0 | v1.28 |
v2.12.0 | v1.29 |
v2.13.0 | v1.30 |
kube-state-metrics 主要功能:
节点状态信息,如节点 CPU 和内存的使用情况、节点状态、节点标签等
Pod 的状态信息,如 Pod 状态、容器状态、容器镜像信息、Pod 的标签和注释等
Deployment、Daemonset、Statefulset 和 ReplicaSet 等控制器的状态信息,如副本数、副本状态、创建时间等
Service 的状态信息,如服务类型、服务 IP 和端口等
存储卷的状态信息,如存储卷类型、存储卷容量等
Kubernetes 的 API 服务器状态信息,如 API 服务器的状态、请求次数、响应时间等
通过 kube-state-metrics 可以方便的对 Kubernetes 集群进行监控,发现问题,以及提前预警
KubeStateMetrics部署
包含
ServiceAccount、ClusterRole、ClusterRoleBinding、Deployment、ConfigMap、Service 六类YAML文件配置rabc
vim KubeStateMetrics-rabc.yaml配置cm
vim KubeStateMetrics-cm.yaml配置deploy和svc
vim KubeStateMetrics.yaml验证cAdvisor
cAdvisor 主要功能:
对容器资源的使用情况和性能进行监控。它以守护进程方式运行,用于收集、聚合、处理和导出正在运行容器的有关信息
cAdvisor 本身就对 Docker 容器支持,并且还对其它类型的容器尽可能的提供支持,力求兼容与适配所有类型的容器
Kubernetes 已经默认将其与 Kubelet 融合,所以我们无需再单独部署 cAdvisor 组件来暴露节点中容器运行的信息
Prometheus 添加 cAdvisor 配置
由于 Kubelet 中已经默认集成 cAdvisor 组件,所以无需部署该组件。需要注意的是,他的指标采集地址为 /metrics/cadvisor,需要配置https访问,可以设置 insecure_skip_verify: true 跳过证书验证
热加载prometheus,使configmap配置文件生效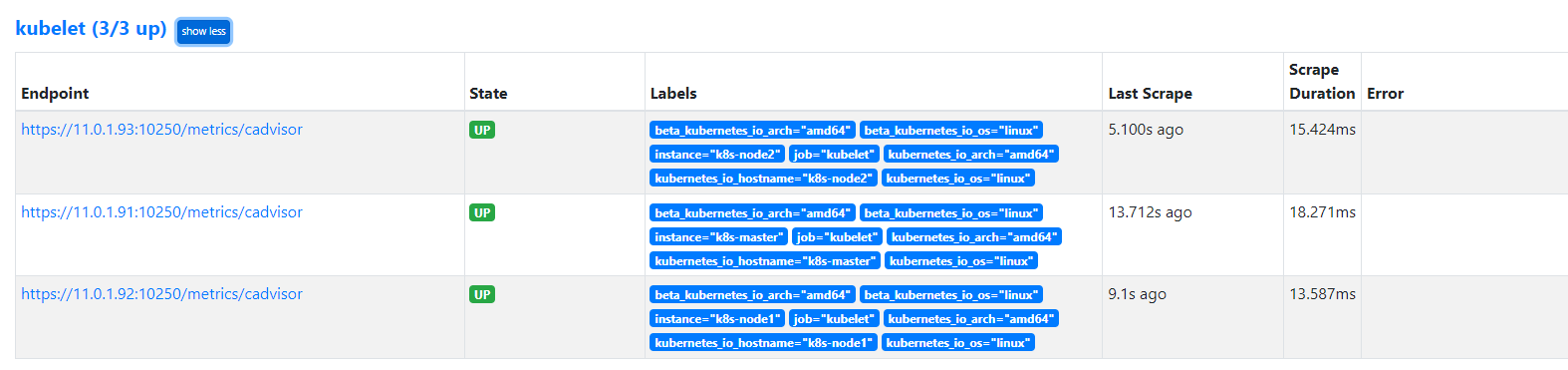
k8s-node 监控
在 prometheus-config.yaml 中新增采集 job:k8s-nodesnode_exporter也是每个node节点都运行,因此role使用node即可,默认address端口为10250,替换为9100即可
热加载prometheus,使configmap配置文件生效:总结
- kube-state-metrics:将 Kubernetes API 中的各种对象状态信息转化为 Prometheus 可以使用的监控指标数据。
- cAdvisor:用于监视容器资源使用和性能的工具,它可以收集 CPU、内存、磁盘、网络和文件系统等方面的指标数据。
- node-exporter:用于监控主机指标数据的收集器,它可以收集 CPU 负载、内存使用情况、磁盘空间、网络流量等各种指标数据
这三种工具可以协同工作,为用户提供一个全面的 Kubernetes 监控方案,帮助用户更好地了解其 Kubernetes 集群和容器化应用程序的运行情况
- 作者:NotionNext
- 链接:https://tangly1024.com/article/145db897-8f81-803a-8f27-dced464a9cc1
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。







